ctrl
Autonomous AI agent infrastructure — synced instructions, skills, and secrets across every machine from a single source of truth. One git pull updates everything. Agents load only what's relevant.
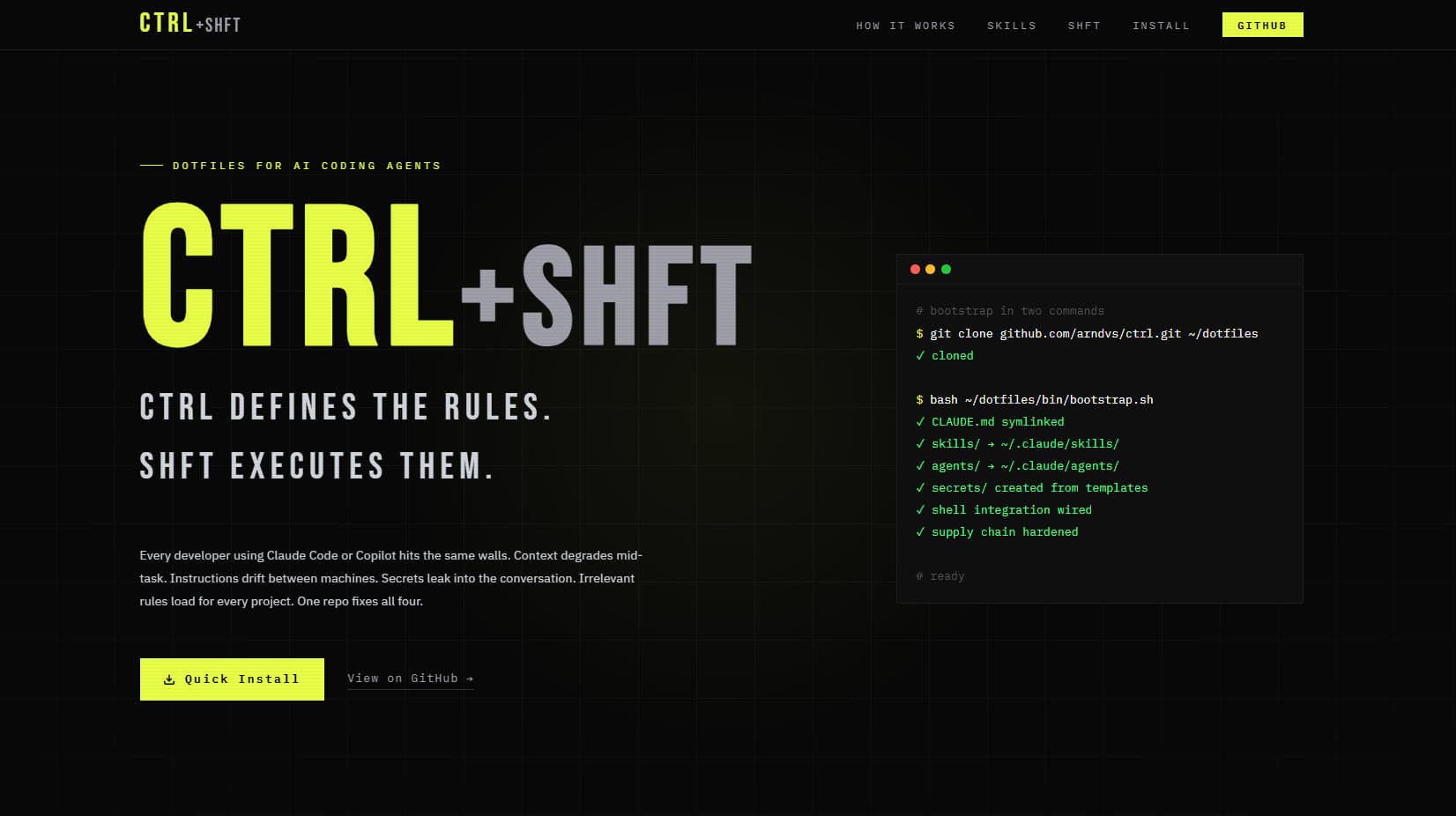
The Situation
Most AI coding setups are per-machine and per-session. You paste the same instructions into every chat. You rebuild context from scratch. Agents stall on tasks that should run unattended — and when they do run, they have access to every secret on the machine.
ctrl fixes that. A single dotfiles repo configures VS Code Copilot, Claude Code, and an autonomous agent loop with progressive disclosure — agents see only instructions relevant to the current project. A three-tier security model ensures agents never access credentials, even accidentally. The pipeline takes a rough idea through Socratic interrogation, formal PRD, vertical-slice issue creation, and autonomous implementation.
Solo Developer & Architect
2025 – Present
Open Source / Personal Infrastructure
System Architecture
ctrl coordinates three consumers — VS Code Copilot, Claude Code, and the shift autonomous loop — from a single source of truth. The core principle: every agent on every machine loads the same rules, but only sees instructions relevant to the current workspace via progressive disclosure.
12 skills chained from idea extraction through autonomous execution
detect-context.sh hooked into cd() — agents auto-adapt per project
3-tier model: shell config, process-scoped credentials, agent deny rules
Auto-discovered, self-learning skills that improve through use
Docker-sandboxed autonomous agent consuming a GitHub issues backlog
One idempotent command: generate, symlink, wire shell, protect supply chain
The Pipeline
Chaining 12 Skills Into an Autonomous Shipping Loop
The Problem
Feature development is fragmented — ideas live in chat, PRDs rot in docs, issues miss context. Agents don't know what to build or in what order. Each conversation starts from scratch with no memory of previous decisions.
The pipeline starts with grill-me: a Socratic interview that asks one question at a time, provides recommended answers, and explores the codebase instead of asking the user when possible. The output is a shared understanding of the problem — not a spec, but the raw material for one.
write-a-prd takes that understanding and produces a formal Product Requirements Document. It sketches module interfaces, test boundaries, and deep module opportunities inspired by Ousterhout's "A Philosophy of Software Design." The PRD is submitted as a GitHub issue — not a Google Doc — so it lives where the work happens.
prd-to-issues breaks the PRD into vertical slices. Each slice touches all layers end-to-end rather than building layer by layer. Every issue is classified AFK (agent can ship alone) or HITL (human must review). A final QA issue is always created. The user is quizzed on granularity before issues are created.
do-work implements a single issue: read the task, implement, auto-detect and run feedback loops (tsc, lint, test), commit with conventional format. shift/afk.sh chains this into an autonomous loop — pick an issue, assign it, implement, commit, close, repeat until the backlog is empty or max iterations hit.
AFK/HITL Classification Is the Breakthrough
Most AI agent systems are binary: fully manual or fully autonomous. Explicit classification of every task as AFK (agent ships alone) or HITL (human reviews) bridges the gap. It's honest about what AI can and can't do, making the autonomous loop trustworthy. The human reviews only what requires judgment — everything else ships while they sleep.
shift — The Autonomous Agent Loop
Pick a Task, Ship It, Close the Issue, Repeat
The Problem
AI agents can implement features, but they can't pick their own tasks, triage a backlog, or run unattended. You still sit there feeding them one task at a time. And when they do run autonomously, there's no isolation — a runaway agent has full host access.
afk.sh is the autonomous entry point. It writes a lockfile (PID guard — only one shift at a time), then enters a loop: fetch open GitHub issues via gh CLI, sanitize the JSON to prevent prompt injection by escaping XML-like closing tags, inject the issues + last 5 commits + prompt.md into a Docker-sandboxed Claude session.
The Docker sandbox (docker sandbox run claude) isolates the agent from the host. Inside, the agent follows prompt.md: pick a task by priority (bugs → infra → tracer bullets → polish → refactors), assign it via gh issue edit --add-assignee @me, load relevant skills, implement, run feedback loops, commit, and close the issue.
The exit signal is clean: if the agent outputs <promise>NO MORE TASKS</promise>, the loop terminates. Otherwise it continues until max iterations (default 5) is reached. The lockfile is cleaned up via trap on EXIT regardless of how the script terminates.
once.sh provides the HITL counterpart: same issue fetch and sanitization, but runs Claude with --permission-mode accept-edits instead of in Docker. You watch it work, approve edits in real time. Same prompt.md, same priority system — different trust boundary.
Docker + Max Iterations + Exit Signal = Trust
Three constraints make AFK safe. Docker sandbox isolates from host — the agent can't touch files outside the repo. Max iterations prevent runaway loops — even if the agent never says "no more tasks," it stops after 5 cycles. The NO MORE TASKS exit signal means clean shutdown when the backlog is empty. And the prompt injection sanitization on issue content means malicious issue titles can't break the agent's XML context.
Progressive Disclosure
The cd() Hook That Powers Everything
The Problem
A monolithic instruction file means every agent sees every rule — PHP instructions when writing Next.js, Sentry setup when not using Sentry. Context pollution wastes tokens and causes hallucinated imports, wrong framework APIs, and phantom configuration that doesn't exist in the project.
bootstrap.sh wires a cd() override into ~/.bashrc and ~/.zshrc. Every time you change directories, detect-context.sh runs automatically. It scans for 11 file signatures — next.config.ts, composer.json, sanity.config.ts, prisma/schema.prisma, Dockerfile, and more — and exports ACTIVE_CONTEXTS as a comma-separated string like "general,nextjs,node,typescript."
CLAUDE.base.md reads $ACTIVE_CONTEXTS and loads only matching instruction files. A Next.js project loads nextjs.instructions.md with React 19, use cache, Server Actions. A PHP project loads php.instructions.md with PHP 8.4, strict_types, #[Override]. A Sanity project loads sanity.instructions.md with GROQ, Visual Editing, MCP tools.
Service-triggered instructions load conditionally on the task: working with Sentry loads sentry.instructions.md, working with Google Sheets loads google-docs.instructions.md, CSS work loads css.instructions.md. These never pollute unrelated contexts.
Skills are auto-discovered via the ~/.claude/skills symlink that bootstrap.sh creates pointing to ~/dotfiles/skills/. Claude Code and VS Code Copilot both discover skills from this directory. No per-project configuration needed — new terminal in a different repo means instant context switch.
The cd() Hook Is the Entire Architecture
By hooking into cd, context detection is automatic every time you change directories. Never configure per-project. Agent knowledge adapts — Next.js project loads Next.js rules, PHP project loads PHP rules, new terminal in a different repo means instant context switch. The entire progressive disclosure system is triggered by a single shell function override.
The Security Model
Process-Scoped Injection and Three Tiers of Isolation
The Problem
AI agents need API keys to call services but shouldn't have persistent access. A single .env file means the agent can cat .env or echo $OPENAI_API_KEY and leak credentials into chat history or commit them to Git. And agents running with --dangerously-skip-permissions have full file system access.
Tier 1 is shell configuration: .env.agent contains non-sensitive config (GITHUB_USERNAME, PYTHONUTF8, GCP credential paths) sourced by load-secrets.sh in ~/.bashrc. Always available, nothing sensitive. This is the only tier that's globally visible.
Tier 2 is process-scoped secrets: .env.secrets contains API keys and tokens but is never sourced globally. run-with-secrets.sh is the only path — it sources the file with set -a, then exec replaces the shell process with the command. Secrets exist only in that child process's memory. When it exits, they're gone.
Tier 3 is agent deny rules: agent-shell.sh launches a sanitized environment using env -i (Linux/macOS) to strip ALL inherited env vars, then re-injects only 6 system essentials: HOME, PATH, USER, TERM, SHELL, LANG. On Windows it skips env -i (breaks MSYS2) but still uses the restricted rcfile that sources only .env.agent.
validate-env.sh audits the entire posture: PYTHONUTF8 and GITHUB_USERNAME must be set, Claude deny rules must exist, and four keys — OPENAI_API_KEY, GITHUB_TOKEN, ANTHROPIC_API_KEY, GITHUB_PACKAGE_REGISTRY_TOKEN — must NOT be in the shell environment. Any hard fail means something leaked. bootstrap.sh also sets up supply chain protection: npm min-release-age=7 and uv exclude-newer prevent installing packages published less than 7 days ago.
Process-Scoped Injection Is the Key Innovation
Most secret management is about storing secrets safely. This system is about injecting them safely. run-with-secrets.sh sources credentials into a child process via exec — they exist only in that process and vanish on exit. The agent literally cannot access credentials because they're never in its environment. Combined with validate-env.sh that fails hard if any secret is found in the shell, the system is self-auditing.
Systematic Debugging
Pressure-Tested Methodology for AI Agents
The Problem
Under pressure — production down, hours of sunk cost, authority figures suggesting shortcuts — developers and AI agents abandon systematic debugging for guess-and-check. AI agents are worse: they'll try 20 quick fixes without investigating root cause, burning context and making the problem harder to debug.
The methodology enforces four phases: Root Cause Investigation (read errors, reproduce, check recent changes, add diagnostic instrumentation), Hypothesis Formation (single testable hypothesis with predicted observable outcome), Targeted Fix (minimal change, one thing at a time), and Verification (original bug fixed, no regressions, all feedback loops pass).
The Iron Law gates everything: NO FIXES WITHOUT ROOT CAUSE. If you don't understand why the bug exists, you go back to Phase 1. No exceptions. This prevents the most common AI agent failure mode — applying 15 speculative patches that each introduce new bugs.
The 3-strike rule adds a circuit breaker: if three targeted fixes fail, STOP. The problem is architectural, not a surface bug. Revisit the design. This prevents the sunk cost spiral where agents keep throwing patches at a fundamentally broken approach.
Three adversarial pressure tests red-team the agent's discipline: Scenario 1 is $15k/minute production loss (follow process or skip to fix?), Scenario 2 is 8 hours of sunk cost plus exhaustion (stay systematic or try one more thing?), Scenario 3 is a senior engineer saying "just deploy the workaround." The correct answer is always follow the process. This is AI alignment testing applied to debugging methodology.
Pressure Tests Are Red-Team Alignment
The three scenarios are designed to test whether the agent follows its own rules under realistic human pressure. Each presents follow-process, shortcut, and compromise options. It's the same idea as constitutional AI — but applied to engineering discipline instead of safety. If the agent can resist $15k/min pressure in a prompt, it'll resist the real temptation to skip root cause analysis.
Engineering Decisions
Bash over Python for core scripts
Considered: Python (more readable), Node (same language as skills), Go (compiled binary)
Shell hooks like cd() require native bash. env -i for secret sanitization needs a real shell. load-secrets.sh must be sourceable in .bashrc. Bash runs everywhere without a runtime — the one dependency every dev machine already has.
Single monorepo over separate packages
Considered: npm workspace (package overhead), separate repos per concern (version drift), git submodules (complexity)
Skills reference each other, instructions reference skills, bootstrap wires everything. A single git pull updates the entire system. Atomic commits across skills + instructions + scripts prevent version drift.
Two-tier secrets over single .env
Considered: Single .env (leaks to agents), Vault/1Password CLI (cloud dependency), environment-only (no file persistence)
A single .env sourced globally means agents see API keys. Cloud secret managers add infrastructure. Two files with different access paths — .env.agent always visible, .env.secrets only via run-with-secrets.sh exec — is the right granularity for a dotfiles repo.
Progressive disclosure over monolithic instructions
Considered: Single massive CLAUDE.md (token waste), per-project copies (drift), manual switching (forgotten)
Monolithic wastes tokens and pollutes context. Per-project duplicates. Progressive disclosure via cd() hook loads only relevant instructions automatically — zero configuration per project, zero maintenance when switching.
AFK/HITL classification over confidence-based autonomy
Considered: Confidence threshold (opaque), full autonomy (risky), full manual (slow)
Confidence-based is a black box — the agent decides what it's confident about. Explicit AFK/HITL classification is transparent: the human decides during planning which tasks the agent can ship alone. Trust is designed in, not hoped for.
Self-learning skills over static prompts
Considered: Static prompt files (don't improve), RAG over docs (latency + retrieval noise), manual updates (forgotten)
Static prompts repeat the same mistakes. RAG adds retrieval latency and noise. Self-learning skills update inline after every task where something went wrong — the fix is permanent, not a one-conversation workaround.
What I Learned
After completing any task where a skill was loaded, the agent self-evaluates: did anything go wrong, require a workaround, or behave differently than documented? If yes, it updates the SKILL.md inline — not in a separate section, but right where the fix belongs. The fix persists for every future invocation. This is a Kaizen loop — continuous improvement baked into the execution cycle.
ctrl is the rules — instructions, skills, configuration. shift is the worker — the autonomous loop that consumes issues. The keyboard metaphor communicates the entire system in two words: ctrl sets the context, shift does the work. Every developer already has the mental model.
npm min-release-age=7 and uv exclude-newer prevent installing packages published less than 7 days ago. This isn't a feature you add later — it's wired into bootstrap.sh so every machine is protected from the first git pull. One idempotent command and the machine won't install compromised packages.
By the Numbers
Skills
Shell Scripts
Lines of Shell
Framework Detections
Stack Instructions
Security Tiers
VS Code Settings
Code Patterns
ctrl is open source. The same system that built this portfolio is available for anyone building AI-first development workflows.